
csp-j1知识点总结
首先声明!!!
- 1、这为本人总结内容,主观性比较强,可以部分借鉴但不建议完全效仿;
- 2、如有使用或转载请注明出处;
- 3、如有不足,欢迎批评指正;
CSP-J 第一轮知识点总结
* 题目类型整理
| 题型 | 知识点类型 | 题目数量 |
|---|---|---|
| 单选 | 信息学史&基本知识 | 8-10 |
| 单选 | C++语法知识点 | 2-3 |
| 单选 | 数据结构&算法 | 3-4 |
| 单选 | 数学&逻辑学&运筹学 | 3-4 |
| 单选 | 比赛相关知识 | 1-2 |
| 问题求解 | 数学 | 1 |
| 问题求解 | 数据结构 | 1 |
| 模拟程序运行 | C++语法&算法 | 4 |
| 完善程序 | C++语法&算法 | 2 |
一、信息学及计算机史
- 计算机的顶级奖项:图灵奖、冯·诺依曼奖
图灵奖:由ACM(美国计算机协会)设立于1966年。是“计算机界的诺贝尔奖”。
冯·诺依曼奖:由IEEE设立。
- 对信息科学做出突出贡献的大神:图灵(所以才有个奖),冯 · 诺伊曼
- 中国获图灵奖的大神:姚期智(清华就有姚班,就是以他的名字命名的)
- 世界第一台电子计算机:埃尼阿克(𝐸𝑁𝐼𝐴𝐶),于1946年2月14日在美国宾夕法尼亚大学诞生。又被叫做电子管计算机。
二、关于编程
- 编程语言:
分两类:面向对象和面向过程。
- 高级语言和低级语言的区别:
高级语言需要编译运行,常数较大,运行速度慢。而低级语言常数极小,运行速度快。此外,高级语言更容易移植。
- 常见低级语言:
汇编
- 面向对象的高级语言:
C++,Java,EIFFEL,Simula 67等。
- 面向过程的高级语言:
C,Fortran语言。
- 递归编程:
递归是指一种通过重复将问题分解为同类的子问题而解决问题的方法。递归式方法可以被用于解决很多的计算机科学问题。简单来讲,就是“自身调用自身”(在函数中)。
- P类/NP类/NPC类问题:
1、P类问题:如果一个问题能找到一个在多项式时间内解决它的算法,那么这个问题就是P问题。
2、NP类问题:注意:NP问题不是非P类问题,而是在多项式时间内验证一个解的问题。或者,我们可以将其理解为在多项式时间内猜出一个解的问题。
3、NPC类问题:定义如下:如果一个问题是NP问题,而且所有的NP问题都可以约化到它。那么它就是NPC类问题。再来介绍一下关于约化的定义:如果一个问题A可以约化为问题B,含义就是这个问题A可以用问题B的解法来解决。
*NOIP / CSP等的历史、大事件、参赛要求(每年都考)
-
NOI:中国计算机学会于1984年(当年,*提出计算机要从娃娃抓起)创办全国青少年计算机程序设计竞赛,即全国青少年信息学奥林匹克竞赛,是国内包括港澳在内的省级代表队最高水平的大赛。
-
NOIP:中国计算机学会于1995年创办全国青少年信息学奥林匹克联赛。NOIP在同一时间、不同地点以各省市为单位由特派员组织。全国统一大纲、统一试卷,初、高中或其他中等专业学校的学生可报名参加。联赛分初赛和复赛,初赛考察通用和实用的计算机科学知识,以笔试为主。复赛为程序设计,须在计算机上调试完成。参加初赛者须达到一定分数线后才有资格参加复赛。联赛分普及组和提高组两个组别,难度不同,分别面向初中和高中阶段的学生。
-
从2005年开始,NOIP不再支持Basic;从2022年开始,不再支持Pascal。
-
选手进入考场时,只许携带笔、橡皮等非电子文具入场。禁止携带任何电子产品或机器设备入场,无存储功能的手表除外;手机(关机)、U盘或移动硬盘、键盘、鼠标、闹钟、计算器、书籍、草稿纸及背包等物品必须存放在考场外。如有违规带入的,一经发现,NOI各省特派员可直接取消违规选手的参赛资格。
-
CCSP:大学生计算机系统与程序设计竞赛,由中国计算机学会(CCF)于2016年发起的一个面向大学生的竞赛,每年举办一次,考察的是算法、编程以及计算机系统设计能力,旨在进一步提高计算机教育质量,使学生通过竞赛进一步学习和掌握计算机系统知识,同时对高校计算机教育产生引领作用。
-
CSP:中国计算机学会于2014年推出CCF计算机软件能力认证,该项认证重点考察软件开发者实际编程能力,由中国计算机学会统一命题、统一评测,委托各地设立的考试机构进行认证考试。该项认证每年大约3、9、12月各举办一次。认证者不限年龄,不限学历,不限报考次数,不限国籍 ,在报名官网注册账户后均可报名参加认证。语言:C/C++(Dev-CPP 5.4.0 (Min GW 4.7.2)),Java(Eclipse (Java SDK 1.7.0_15)),Python(3.6.5) 浏览器:Chrome
CSP认证考试可以带纸质资料进入考场,不过只能是常用语言的程序设计基础书、数据结构的相关书籍。不允许U盘、手机等电子设备进入考场。
CSP-S/J:认证开始15分钟后,认证者不能再进入认证点。如有认证者提前离开认证点,除身体特别原因外,须在认证进行2小时后方可准予离开。在第一轮认证期间,任何人不得将试卷携带出考场。认证者进入考场时,监考检查认证者携带物品。认证者只许携带笔、橡皮等非电子文具入场。禁止携带任何电子产品或机器设备入场,无存储功能的手表除外;手机(关机)、U盘或移动硬盘、键盘、鼠标、闹钟、计算器、书籍、草稿纸及背包等物品必须存放在考场外。如有违规带入的,一经发现,CSP-J/S认证总负责人可直接取消违规认证者的参加资格。
三、关于计算机
先上张大图:
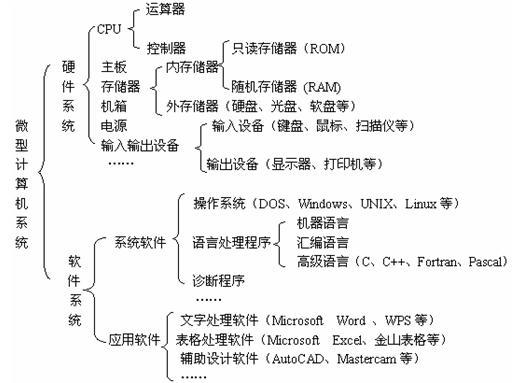
-
重要设备:
硬件组成:
- 控制器(Control):是整个计算机的中枢神经,其功能是对程序规定的控制信息进行解释,根据其要求进行控制,调度程序、数据、地址,协调计算机各部分工作及内存与外设的访问等。
- 运算器(Datapath):运算器的功能是对数据进行各种算术运算和逻辑运算,即对数据进行加工处理。
- 存储器(Memory):存储器的功能是存储程序、数据和各种信号、命令等信息,并在需要时提供这些信息。
- 输入设备(Input system):输入设备是计算机的重要组成部分,输入设备与输出设备合称为外部设备,简称外设,输入设备的作用是将程序、原始数据、文字、字符、控制命令或现场采集的数据等信息输入到计算机。常见的输入设备有键盘、鼠标器、光电输入机、磁带机、磁盘机、光盘机等。
- 输出设备(Output system):输出设备与输入设备同样是计算机的重要组成部分,它把外算机的中间结果或最后结果、机内的各种数据符号及文字或各种控制信号等信息输出出来。微机常用的输出设备有显示终端CRT、打印机、激光印字机、绘图仪及磁带、光盘机等。
-
CPU及存储:
CPU(中央处理器)=运算器+控制器+寄存器
运算器=算术逻辑运算单元(ALU)及浮点运算单元(FPU)
存储器=内存储器+外存储器
BIOS是英文"Basic Input Output System"的缩略语,直译过来后中文名称就是"基本输入输出系统"。其实,它是一组固化到计算机内主板上一个ROM芯片上的程序,它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检程序和系统自启动程序。 其主要功能是为计算机提供最底层的、最直接的硬件设置和控制。
随机存储器RAM的“随机”指“随时访问”
所以,我们记下来以下知识点:
断电后可以保存数据:硬盘,ROM
断电后不可以保存数据:显存(显卡内存),RAM,CPU
- 计算机各存储单位及进位关系:
计算机的存储单位有以下几种:
$$
𝑇𝐵/𝐺𝐵/𝑀𝐵/𝐾𝐵/𝐵
$$
他们之间的进位关系为 $1024$
特殊地,$1B=8(bit)$ ,这里的 $𝑏𝑖𝑡$ 是二进制下的一位内存。
* 机内代码及其运算
原码:设X,若为非负数,则符号位为0,其余各位取值不变,否则符号位为1。如:
X=+1110001,则[X]原=01110001;X=-1110001,则[X]原=11110001。
反码:设X,若为非负数,则与原码相同,否则符号位为1,其余各位取值求反。如:
X=+1110001,则[X]反=01110001;X=-1110001,则[X]反=10001110。
补码:设X,若为非负数,则与原码相同,若为负数,则为反码加1。如:
X=+1110001,则[X]补=01110001;X=-1110001,则[X]补=10001111。
负补:对补码(包括符号位)的每一位求反,且最低位加1。如:
X=+1110001,[-X]补=10001111。
[X+Y]补=[X]补+[Y]补,[X-Y]补=[X]补-[Y]补=[X]补+[-Y]补(最高位产生的进位要丢掉)
四、进制及进制转化
十进制转任意进制
将十进制转换成N𝑁进制,只需把十进制数每次除N𝑁求余数,然后把余数逆序写出来。
看不懂就看图:
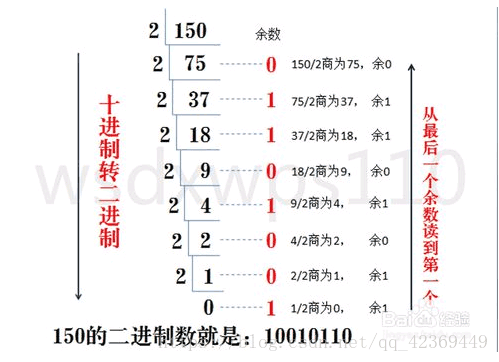
这是二进制的图,其他进制就类比推一下就可以了。如果这个看不懂的话就不要参加初赛了,50块钱买点啥不好…
任意进制转十进制
简单说就是:按位转,第i𝑖位的数字乘以要转换的进制的𝑛−1次幂即可。
还是上图:
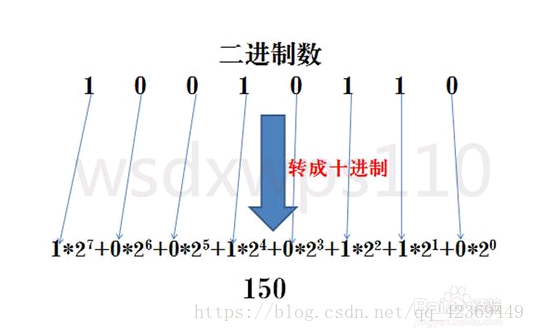
任意进制互相转化
这里考虑用十进制做中转,先把A𝐴进制转十进制,再把十进制转B𝐵进制。
关于小数的进制转换
十进制转任意进制的小数不进行除法运算,而进行乘法运算后取整,取整后从前向后排列。
任意进制转十进制的小数只需要乘上负指数,最后算出来即可。
各进制的字母表达
$𝐻(𝐻𝑒𝑥𝑎𝑑𝑒𝑐𝑖𝑚𝑎𝑙)——16进制$
$𝐷(𝐷𝑒𝑐𝑖𝑚𝑎𝑙)——10进制$
$𝑂(𝑂𝑐𝑡𝑜𝑛𝑎𝑟𝑦)——8进制$
$𝐵(𝐵𝑖𝑛𝑎𝑟𝑦)——2进制$
二进制的相关知识
二进制是计算机进行计算所使用的工具,自然也是非常常考的要点。二进制的相关知识有许多,甚至算法中的位运算也是二进制的相关内容,但为了过第一轮初赛,我们只介绍一些理论知识。关于位运算的相关知识请有兴趣的同学自己学习。
- 1、原码
顾名思义,原码就是十进制数直接转换成二进制之后直接形成的二进制编码。
- 2、补码
正数的补码是本身,负数的补码是其反码加一。
- 3、反码
顾名思义:正数的反码是本身,负数的反码是其除符号位之外的所有位按位取反的结果。
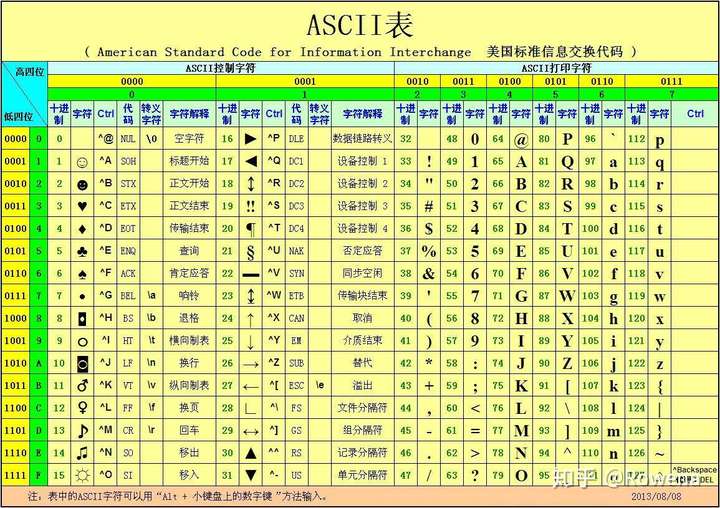
附:ASCII码
ASCII(American Standard Code for Information Interchange,美国标准信息交流码)码是目前微型计算机中使用最广泛的一种字符编码,用7位二进制数来编码(占一个字节),可表示128个字符,最高位为0或作奇偶校验用。
五、位运算
位运算不仅在初赛中是一个知识点分类,在复赛(即真正的程序设计与运用)的时候也有很大的一个应用。而且,位运算的相关知识是计算机运算的灵魂,更是每个程序猿应该理解的一种基本操作。
1、与(&)运算
(1)运算法则
两个二进制数进行与&运算,如果对应位都为1则结果为1,否则为0.
(2)技巧及用途
与运算常常用于二进制下的取位操作。想要知道二进制下的某位是否是1,就&上这个位数对应的十进制数。假如返回的是这个十进制数本身,则这个位的确是1,反之就是0.
比如:
我们要取第三位是否为1,我们只需要与&上第三位(二进制表示为100)对应的二进制数4,如果返回值为4,就代表第三位为1,反之就是0.
最常用的是取二进制下的最末位,即a&1。这样的技巧可以用于判断奇偶,根据二进制常识,尾数为1则为奇数,反之为偶数。
2、或(|)运算
(1)运算法则
两个二进制数进行或|运算,如果对应位有一个为1,结果就为1.只有在两个数的对应位置都是0的时候,结果才为0.
(2)技巧及用途
或运算常用于二进制特定位的赋值。想把哪个位强行变成1,就用这个数|上这个位数对应的二进制数。
还是上面那个例子,我们想让00000的第三位变成1.即十进制变4,我们直接|上4就可以。
当然,不同于&运算,我们很少用|运算进行任意位赋值。通常来讲,我们只使用a|1把a的最后一位强行变成1,其实质意义是把原数加一。或者使用a|1-1再把它变为0.这个技巧通常用于把它变成它最接近的偶数。
3、异或(^)(xor)运算
(1)运算法则
两个二进制数进行异或(^)运算,如果对应位相同,不管是0或者是1,都返回1,反之返回0.
(2)技巧及用途
其实没啥用途…
好吧,我介绍一个性质:一个数经过两次异或之后等于原数。
(很好理解)
4、非(~)运算
(1)运算法则
把给定二进制数全部取反。
(2)技巧及用途
其实没什么运算上的用途,本蒟蒻曾看见一些大佬用这个运算判断输入是否为0…
大约长这个样子:
1 | while(~scanf("%d",&n)) |
5、左移(<<)运算
(1)运算法则
a<<b 表示把 a 的二进制位向左移动b位,低位用0补上。
(2)技巧及用途
根据二进制的常识,我们会发现,二进制第k位上的数就等于 $2^{k-1}$。(从0开始计位)
比如,二进制下的100就是 $2^{3-1}=4$。
所以我们发现,左移运算 a<<b 的实质就是 $𝑎×2^k$。
左移运算最常用的技巧就是用来代替×2的整数次幂的乘法运算。因为我们普遍认为,位运算是要比四则运算加减乘除及模运算更快一些的运算。
6、右移(>>)运算
(1)运算法则
a>>b就是把a的二进制位向右移动b位,溢出的舍去。
(2)技巧及用途
类比于左移运算,我们发现右移运算就是把a除以2的整数次幂。这就是右移运算的用途——优化除法运算。
这里需要特殊说明的是,右移算法可以用在数学知识中的求最大公约数的程序块上。因为mod运算的效率慢的出奇,所以我们可以用右移运算来进行除以2的操作。据说可以提高 60% 的效率。
7、位运算优先级
位运算的优先级是我们在处理位运算的时候常常要考虑的问题,诚然,我们可以用括号强制位运算的顺序,但是,我们还是应该学会位运算的优先级(这应该是常识)。
位运算的优先级如下:
按位反(~)>位移运算(<<,>>)>按位与(&)>按位异或(^)>按位或(|)
附:位运算在状压DP的用法
众所周知,状压DP就是把状态压缩成一个01串(其实就是一个二进制数),用以减少DP数组的维数。但是我们在DP的时候就要按照01串来进行状态的转移。所以位运算是状压DP的基础知识和必备知识。所以我在本篇随笔的末尾还附上了状压DP中比较常用的操作及其二进制实现的方式。
正文:(本文中的a表示十进制下的整数)
1、获得第i位的数字:(a>>i)&1 或者 a&(1<<i)
很好理解,我们知道可以用&1来提取最后一位的数,那么我们现在要提取第i位数,就直接把第i位数变成最后一位即可(直接右移)。或者,我们可以直接&上1左移i位,也能达到我们的目的。
2、设置第i位为1:a=a|(1<<i)
我们知道强制赋值用|运算,所以就直接强制|上第i位即可。
3、设置第i位为0:a=a&(~(1<<i))
这里比较难以理解。其实很简单,我们知道非~运算是按位取反,(1<<i)非一下就变成了第i为是0,其它全是1的二进制串。这样再一与原数进行&运算,原数的第i位无论是什么都会变成0,而其他位不会改变(实在不明白的可以用纸笔进行推演)。
4、把第i位取反:a=a^(1<<i)
1左移i位之后再进行异或,我们就会发现,如果原数第i位是0,一异或就变成1,否则变成0。
5、取出一个数的最后一个1:a&(-a)
学过树状数组的同学会发现,这就是树状数组的lowbit。事实上,这和树状数组的原理是一样的。我想,不需要我多解释。
为了应对初赛的笔试题,建议读者在阅读完这篇博客之后至少应该掌握:各种位运算的运算法则以及位运算优先级。
另外,对于位运算的优先级,本蒟蒻在后面的逻辑运算部分还会有详细的解析。
逻辑运算
逻辑运算
逻辑运算一共有三种,每种都有两种写法:
逻辑非:!或 ┐
逻辑与:&& 或 ∧
逻辑或:|| 或 ∨
逻辑运算的优先级
非>>与>>或
位运算+逻辑运算的优先级
逻辑非(!,┐)=按位反(~)>位移运算(<<,>>)>不等号(>=,<=)>等号(==,!=)>按位与(&)>按位异或(^)>按位或(|)>逻辑与(&&,∧)>逻辑或(||,∨)
逻辑表达式
由逻辑运算复合而成,只有两种结果:𝑡𝑟𝑢𝑒和𝑓𝑎𝑙𝑠𝑒,在C/C++中,返回的值以0表示假,以1表示真。
条件表达式
条件表达式的基本形式如下:
<表达式1>?<表达式2>:<表达式3>
其表达意义是:如果表达式1成立,则执行表达式2,否则执行表达式3。其实也等价于𝑖𝑓−𝑒𝑙𝑠𝑒条件语句。例如下:
1 |
**注意:**如果条件表达式有多个进行复合,那么在执行的时候需要从由往左依次判断最后得出一个结果。即:右结合性。
比如:
<表达式1>?<表达式2>:<表达式3>?<表达式4>:<表达式5>
那么,在执行的时候是从3开始判断是否为真,然后执行某一个表达式,依次向上回溯。
六、简单数据结构基本理论
1、链表
本篇随笔就数据结构——链表进行讲解。链表是一种特别实用的数据结构,我把它理解为数组的升级版,也就是在数组的基础上,它能做到在任意位置添加或者删除元素,而不影响其他元素。链表还是我们进行图论学习时,图的常用存储方式——邻接表(链式前向星)的实现基础。学习链表需要读者具有一定的语法基础,最好会一点点指针。(不会也没关系,我们主要讲解数组模拟链表)
什么是链表
链表,顾名思义,就是带链的表。我已经说过,链表属于数组的加强版。那我们可以借助数组来理解链表:如果说数组是一长排连在一起的“方块”的话,那么链表就是把这些方块“拉开“,每个方块还有两个箭头,分别指向这个方块前面的方块和后面的方块。
这样我们就可以理解,为什么链表可以支持随机插入和删除了。从某种意义上来说,这里的每一个方块都是离散的,我们在某两点插入的时候,只需要把要插入的元素,这个元素目标位置前面的元素、后面的元素的箭头改一下,就做到了插入的操作。删除同理。
链表的实现原理
根据刚才的理解,我们可以发现,我们可以用一个结构体来模拟每一个方块,结构体中存一个元素和两个指针,指针分别指向上一个元素的位置和下一个元素的位置。但是蒟蒻不会指针指针的实现比较麻烦,而且在调试的时候也不是很理想。所以我们来想指针的本质就是告诉你一个位置,那么针对于”加强数组“链表来讲,这个位置可以用什么来表示呢?
对,数组下标。
所以我们刚才的结构体就可以简化,变成存一个元素和两个int变量(存储数组下标)。这样,我们就可以用结构体数组模拟链表的实现。
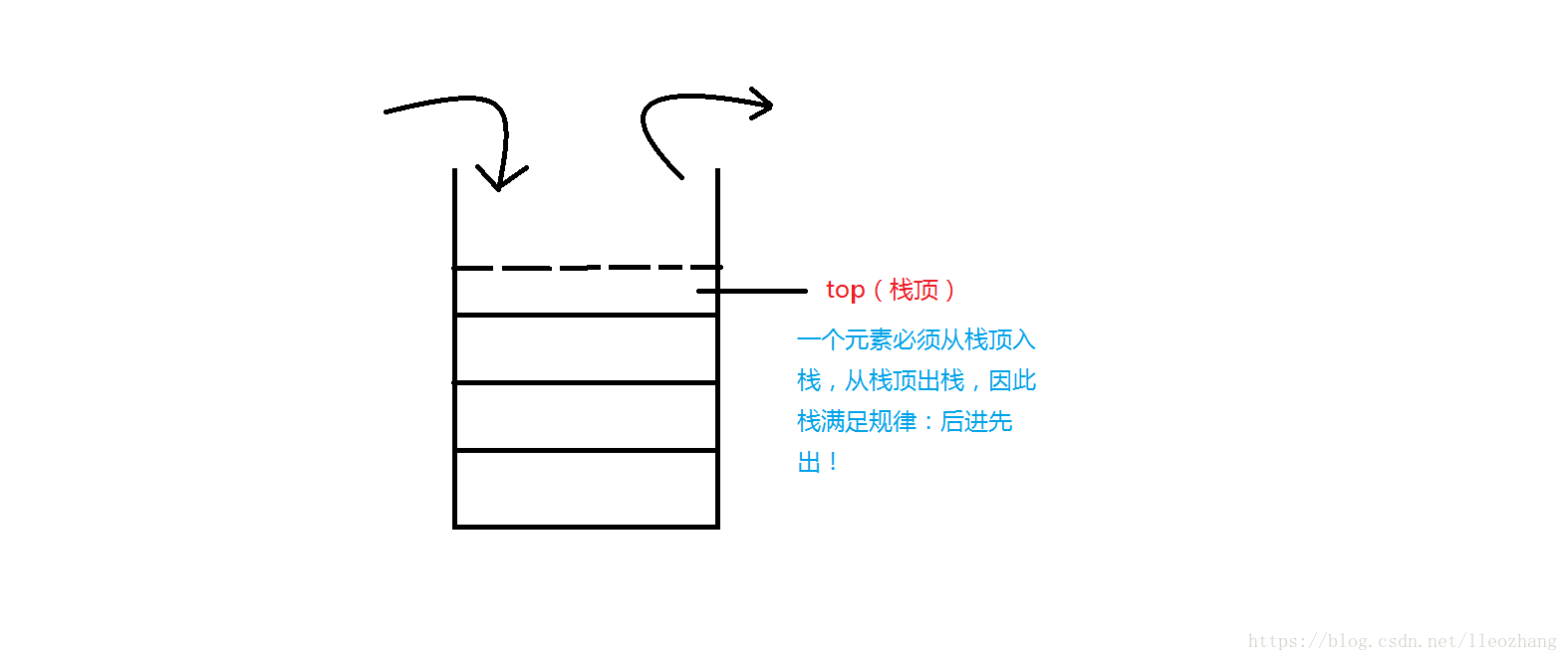
2、栈
想象一个桶,你从上面往里扔砖,然后你想把某一块砖拿出来,你需要先拿出来你后扔进去的砖。这就是栈。栈的基本原则是:后进先出
来一发图示?
浅谈前、中、后缀表达式
前、中、后缀表达式是信息学奥林匹克竞赛中比较鸡肋的知识点。但是知识点在考纲范围内,而且中缀表达式转后缀表达式是比较有用的知识。所以在这里为大家简单介绍一下。
前缀表达式(少用)
又称波兰式(Polish Notation),操作符以前缀形式位于两个运算数前(如:3+2的前缀表达形式就是+ 3 2)。
中缀表达式
操作符以中缀形式位于运算数中间(如:3+2),是我们日常通用的算术和逻辑公式表示方法。
例子:
$$
6×12+9−14。
$$
后缀表达式
又称逆波兰式(Reverse Polish Notation - RPN),操作符以后缀形式位于两个运算数后(如:3+2的后缀表达形式就是3 2 +)。
例子:(注意!正常写是没有逗号的,这里方便区分)
$$
6 ,12 ,× ,9 ,+ ,14 ,-
$$
后缀表达式转中缀表达式的实现:
从左至右依次遍历后缀表达式各个字符(需要准备一个运算数栈存储运算数和操作结果)
1、字符为 运算数 :
直接入栈(注:需要先分析出完整的运算数并将其转换为对应的数据类型)
2、字符为 操作符 :
连续出栈两次,使用出栈的两个数据进行相应计算,并将计算结果入栈
注意:第一个出栈的运算数为 a ,第二个出栈的运算数为 b ,此时的操作符为 - ,则计算 b-a (注:a和b顺序不能反),并将结果入栈。
3、重复以上步骤直至遍历完成后缀表达式,最后栈中的数据就是中缀表达式的计算结果。
还拿上面的例子:
$$
6 ,12 ,× ,9 ,+ ,14 ,-
$$
上面的式子就可以写成如下的中缀表达式:
$$
6×12+9−14。
$$
- 特别注意:针对一个确定的中缀表达式,其所对应的后缀表达式不唯一;而针对一个确定的后缀表达式,其对应的中缀表达式是唯一的。
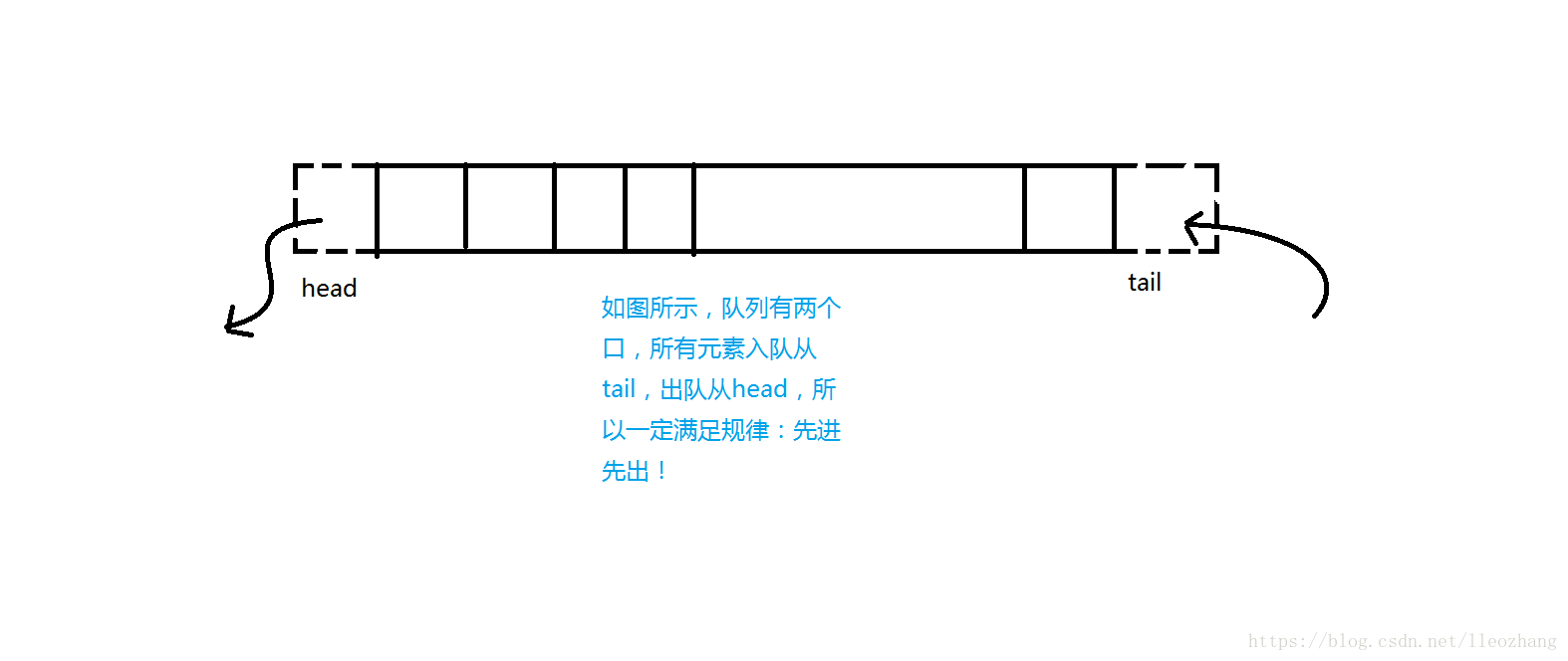
3、队列
想象你在排队买票,这个队伍中的人都非常有素质,都自觉排队而且不会提前离开队伍。这样就只能从队首买完票再离开,从队尾进入队伍。队列的基本原则是:先进先出。
再来一发图示:
4、字符串
字符串子串的概念:字符串是一串字符(废话),它的子串被定义为:字符串中任意个连续的字符组成的子序列。
字符串子串个数的计算公式:
$$
\frac{n×(n+1)}{2}+1
$$
(就是字符串长度等差数列)
如果是非空子串,就把那个一减去即可(子串个数的公式加一就是考虑空子串的情况)。
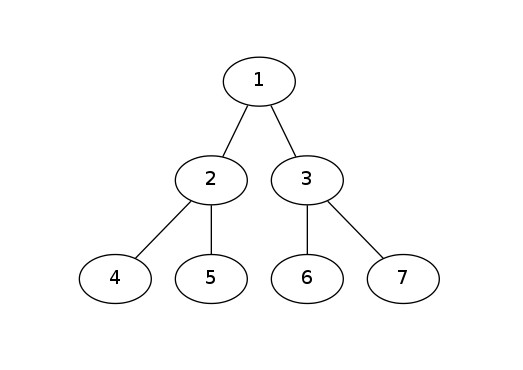
5.树
emmm…直观来讲,就是一张长得像树的图。定义是任意两点之间的简单路径有且只有一条。树是一棵连通且无环的图。它的边数是𝑛−1。
二叉树的遍历
二叉树有不同的遍历方式,一般来讲,我们将其分成三类:先序遍历(也叫先根遍历)、中序遍历(中根遍历)以及后序遍历(后根遍历)。
- 先序遍历:遍历方式如下:根—左儿子—右儿子
- 中序遍历:遍历方式如下:左儿子—根—右儿子
- 后序遍历:遍历方式如下:左儿子—右儿子—根
我们用一张图来理解一下这几种遍历方式。
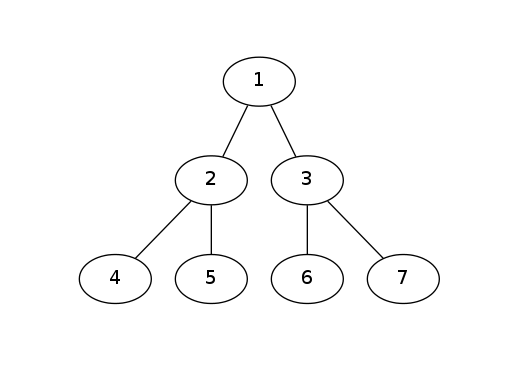
这张图的先序遍历:1245367
中序遍历:4251637
后序遍历:4526731
-
一个推论:
先序遍历+中序遍历=一棵确定的二叉树
后序遍历+中序遍历=一棵确定的二叉树
先序遍历+后序遍历=啥也不是
特殊二叉树及其性质
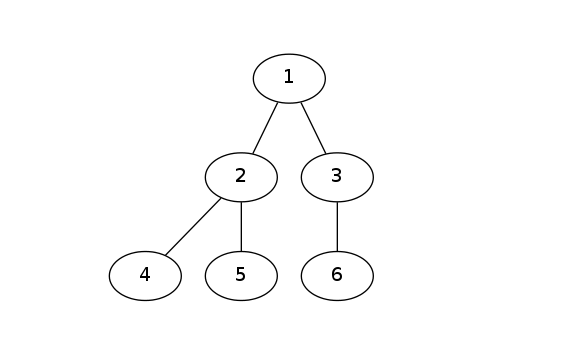
- 完全二叉树:只有最后一层不是满的,且最后一层的所有节点均集中在左侧。
图例如下:
- 满二叉树:节点个数已满。
图例如下:
- 特殊二叉树的性质:
1、对于一棵完全二叉树来讲,它的叶子节点为 $𝑛$,则节点总数为 $2×𝑛−1$。此结论可逆。
2、对于一棵满二叉树来讲,它的层数(深度)为 $𝑘$,则它的节点总数为 $2×𝑘−1$。此结论可逆。
拓扑排序(这个先不讲)
6.图论
图(Graph)是图论中的一个重要概念,用于描述由节点(顶点)和连接这些节点的边(或弧)组成的非线性数据结构。
图的基本概念:
-
顶点(Vertex):图中的基本单位,通常用于表示实体或节点。
-
边(Edge):连接图中两个顶点的关系。边可以是有向的(有方向性,称为弧)或无向的(无方向性)。
-
路径(Path):顶点序列,其中每两个相邻的顶点通过一条边连接。
-
环(Cycle):路径中第一个顶点等于最后一个顶点的路径。
-
连通图:顾名思义,连通图就是连通的图,即任意两点都能直接或间接到达,这就区别于完全图必须直接用边到达的定义。
-
完全图:任意两点都有边相连,我们很容易推出来,一张完全图的边数为(𝑛为节点个数)
$$
\frac{n×(n−1)}{2}
$$
-
无向图(Undirected Graph):所有边没有方向的图。
-
有向图(Directed Graph):图中的边有方向性的图。
-
权重(Weight):边或弧上关联的数值,通常用于表示边的成本或距离。
图的邻接矩阵存储:
邻接矩阵是用二维数组表示图的一种常见方法,其中数组元素表示顶点之间的连接关系。
定义:对于一个有n个顶点的图,邻接矩阵是一个n x n的矩阵,其中元素 a[i][j] 表示顶点 i 和顶点 j 之间是否有边或弧。如果是无向图,通常用1表示连接,0表示没有连接;如果是有向图,可以用1表示有边,0表示没有边,或者用权值表示边的权重。
优点:
- 简单直观,易于理解和实现。
- 方便查找任意两个顶点之间是否有边。
缺点:
- 浪费空间:对于稀疏图(边数量远少于顶点数量),大部分矩阵元素为0,造成空间浪费。
- 不适合大规模图:当顶点数量非常大时,邻接矩阵的空间消耗会很大。
图的邻接表存储:
邻接表是用链表或者类似的数据结构表示图的另一种常见方法,适合表示稀疏图。
定义:使用数组和链表的结合来表示图。数组的每个元素对应一个顶点,每个元素存储与该顶点相邻的所有顶点(即与其有边直接连接的顶点)的链表或者列表。
优点:
- 省空间:对于稀疏图,只存储存在的边,节省了空间。
- 插入和删除效率高:对于边的插入和删除操作,相较于邻接矩阵更加高效。
缺点:
-
不便于查找任意两个顶点之间的关系:需要遍历链表来确定两个顶点是否相连,效率低于邻接矩阵。
-
需要额外空间来存储链表或列表。
在实际应用中,选择邻接矩阵还是邻接表取决于图的稀疏程度和需要的操作类型。稠密图适合用邻接矩阵表示,而稀疏图通常用邻接表表示。
七、时空复杂度的计算
- 时间复杂度:渐进时间复杂度用符号 $𝑂$ 表示。一个程序的语句执行次数可以用一个代数式表示,那么我们取这个代数式的最高次项且忽略此项系数作为时间复杂度。如果一个程序的语句执行次数为 $2𝑛^3+3𝑛^2+𝑛+7$,那么这个程序的渐进时间复杂度为 $𝑂(𝑛^3)$ 。
- 计算非递归程序的时间复杂度:简单粗暴,数循环。
- 常数:常数即为我们忽略掉的𝑂中最高次项的系数与低次项所带来的时间消耗。
- 空间复杂度:类比时间复杂度。看开空间开了多大。
- 计算空间占用量:根据我们以上说过的计算机存储单位的知识:一个𝑖𝑛𝑡占用的内存是4𝐵,所以我们把开的𝑖𝑛𝑡乘上4,再除以1024就是𝐾𝐵,同理,再除1024就是𝑀𝐵。
公式:𝑛为元素个数,𝑀为最终答案(以𝑀𝐵为单位)
$$
M=\frac{4𝑛}{1024×1024}
$$
$PS:一般来讲,比赛中所给的 256𝑀𝐵 内存可以开 6×10^7 个 𝑖𝑛𝑡 类型的变量。另外,大数组必须开全局变量。如果扔在主函数里极容易爆栈。$
八、数学、逻辑学及运筹学知识
1、排列和组合的定义
(1)排列的定义
从 $𝑛$ 个不同元素中,选出 $𝑚$ 个元素按照一定顺序排成一列,叫做从 $𝑛$ 个不同元素中取出 $𝑚$ 个元素的一个排列。
(2)排列数的定义
从 $𝑛$ 个元素中选出 $𝑚$ 个元素的所有排列的个数,叫做从 $𝑛$ 个不同元素中取出 $𝑚$ 个元素的排列数。
(3)全排列的定义
当 $𝑛=𝑚$ 时所有的排列情况叫做全排列。
(4)组合的定义
从 $𝑛$ 个不同元素中,选出 $𝑚$ 个元素并成一组,叫做从 $𝑛$ 个不同元素中取出 $𝑚$ 个元素的一个组合。
(5)组合数的定义
从 $𝑛$ 个元素中选出 $𝑚$ 个元素的所有组合的个数,叫做从 $𝑛$ 个不同元素中取出 $m$ 个元素的组合数。
(6)排列&组合的区别
通俗地说,组合不分顺序,而排列分顺序,也就是说,对于数列 $1,2$ ,有以下两种排列:$1,2$ 和 $2,1$ ,但是仅有一种组合 $1,2$ 或 $2,1$ 。
2、排列&组合的公式
(1)关于排列的公式
从 $𝑛$ 个不同元素中,选出 $𝑚$ 个元素的排列数,数学表示为:$𝐴_{𝑛}^𝑚$.
计算公式如下:
$$
𝐴_{𝑛}^𝑚=𝑛(𝑛−1)(𝑛−2)⋯(𝑛−𝑚+1)=\frac{𝑛!}{(𝑛−𝑚)!}
$$
(2)关于组合的公式
从 $𝑛$ 个不同元素中,选出 $𝑚$ 个元素的组合数,数学表示为:$𝐶_{𝑛}^𝑚$.
计算公式如下:
$$
𝐶_{𝑛}^𝑚=\frac{𝐴_{𝑛}^𝑚}{𝑚!}=\frac{𝑛!}{𝑚!(𝑛−𝑚)!}
$$
(3)关于全排列的公式
某个数列的全排列数 $𝑓(𝑛)$,计算公式如下:
$$
𝑓(𝑛)=𝑛!
$$
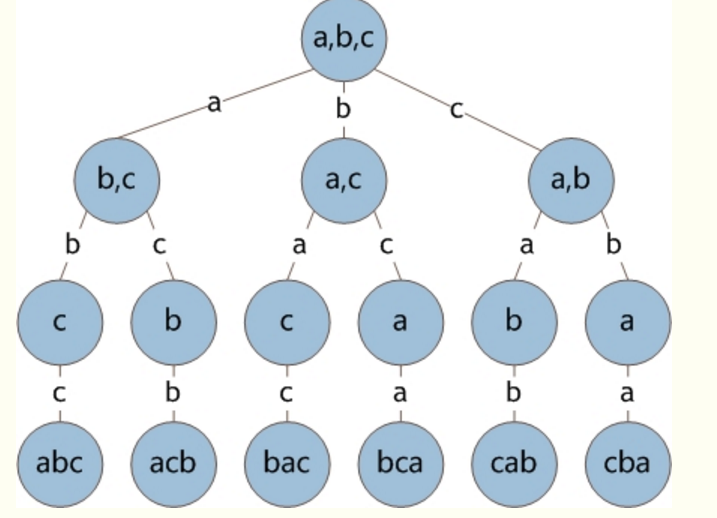
3、全排列的求法
给定 $𝑛$ ,生成 $1−𝑛$ 的全排列。
我们考虑用递归来解决全排列问题:
递归出口是当 $x==n+1$ 地时候,绝对不能仅仅等于 $n!$
我们的递归部分使用标记数组和数列数组实现,具体实现方法可以参照下图:
九、算法
1.算法的基本概念
算法的特征:有穷性,确切性,至少一个输出,可行性
表示方法:自然语言法,程序流程图法(顺序结构,选择结构,循环结构),程序法
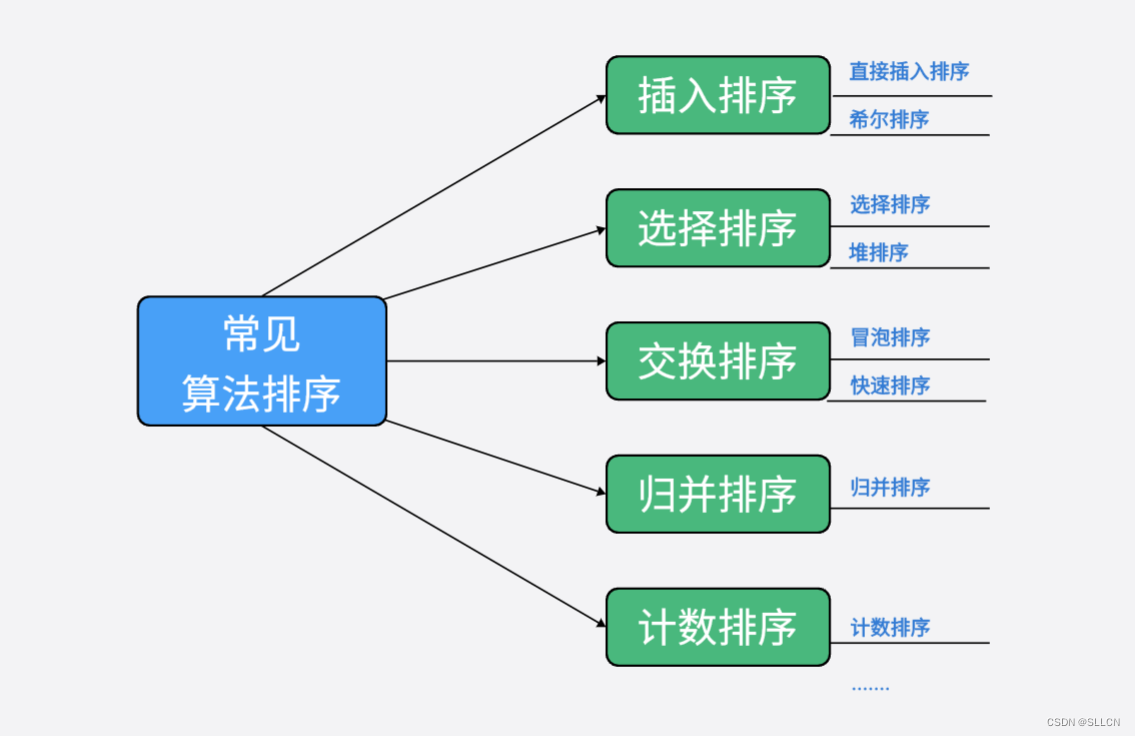
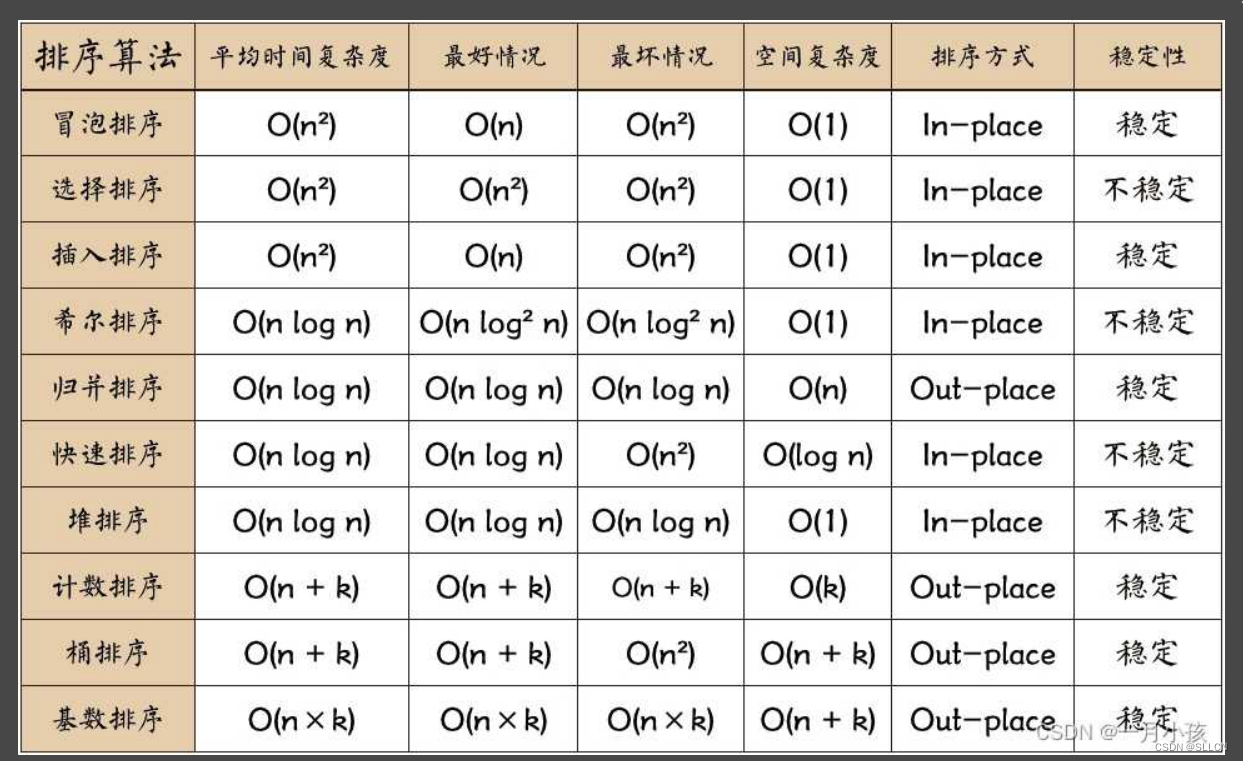
2.排序
- 选择排序:对待排序的记录序列进行n-1遍的处理。第一遍处理是将L[1…n]中最小者与L[1]交换位置,第二遍处理是将L[2…n]中最小者与L[2]交换位置,以此类推,时间复杂度为O(n^2) )。选择排序是稳定排序。
- 插入排序:经过i-1遍处理后,L[1…i-1]已排好序。第i遍处理仅将L[i]插入L[1…i-1]的适当位置p,原来p后的元素一一向右移动一个位置,使得L[1…i]又是排好序的序列,时间复杂度为O(n^2 )。插入排序是稳定排序。
- 冒泡排序:又称交换排序。对待排序的记录的关键字进行两两比较,如果发现是反序的,则进行交换,时间复杂度为O( n^2 )。冒泡排序是稳定排序。
- 希尔排序:先将待排序列进行预排序,使待排序列接近有序,然后再对该序列进行一次插入排序,此时插入排序的时间复杂度为O(n)。
- 快速排序:先从数据序列中选一个元素,并将序列中所有比该元素小的元素都放在它的一边,再对左右两边分别用同样的方法处理,直到每一个待处理的序列长度为1,处理结束。时间复杂度下限为O(nlogn),上限为O( n^2 )。快速排序是不稳定排序,基于分治思想。
- 归并排序:归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。时间复杂度为O(nlogn)。
考试用到的其他基础算法板子将在我另外一篇博客里。
十、程序阅读
阅读程序及完善程序题答题方法
(1)阅读程序和完善程序两个大题在CSP考试当中占据70分,也就是一多半。所以,前面的选择题全对也只能得个30分。这种题不要求必须全对,但是想进入普及组复赛,必须保证拿到70%~80%(约合49~56分)的分值
(2)题型:
① 阅读程序先给一个完整的程序,再给2~3个判断题和1~2个选择题,类似于阅读理解。除特殊说明外,判断题一个1.5分,选择题一个3分。
②完善程序先给一个有残缺部分的程序,再把合适的代码依次填入空中,均为选择题(一个题3分)。类似于完形填空
(3)答题技巧
① 拿到卷子不用先看代码,先看题,在根据题干有目的地阅读代码的相应片段
② 不要一上来就先看第一题,第一题不会就死磕。先找突破口,就是那种非常好填的空,先填上后再加分析,推出其他题的答案。有的代码前后有关联,可以根据前后联系推出答案
③ 碰到特别长的程序千万不要惊慌。出一条长代码可能有这几点原因:1.这个程序所涉及的算法确实需要很长的代码;2.故意的,写一个特别长的代码纯粹就是一个考验,看看哪些人遇到这样的题不会慌张。也就是,有的长代码就是个纸老虎,静下心好好分析,不难。
④ 这种题也要看平时的积累以及扎实程度。多背一些算法的模板代码及例题,这种题拿五十多分也并非难事
 wechat
wechat



